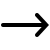
You know, working on recognizing faces when people are wearing things like masks has actually been quite a tough challenge in the field of computer vision. Imagine the struggle of identifying someone who's wearing a face mask! But there's this interesting idea called "masked face analysis via multi-task learning" that's helping us do better in understanding faces even when they're partially covered.
So, in this research work, what we did was come up with a smart way to predict three things about people who are wearing face masks: their age, gender, and emotions. We created a new dataset called FGNET-MASK, which is all about faces with masks. Now they had the tools they needed to solve the problem.
The magic is a "multi-task deep learning model." It's like a powerful multitasking computer programme. It uses its smart internal systems to determine the age, expression (or emotions), and gender of the person behind the mask from these masked faces. It's notable that this model is good at exchanging knowledge between tasks, hence the name "multi-task."
The nice part is that we extensively tested this setup. We compared their new framework to others to discover which performed better. And guess what? Our procedure was more accurate and effective than others. They've taken on the issue of recognising faces with masks, constructed a sophisticated system that can guess about the persons behind the masks, and proved that our method performs better than before. This is a big step forward in computer vision!
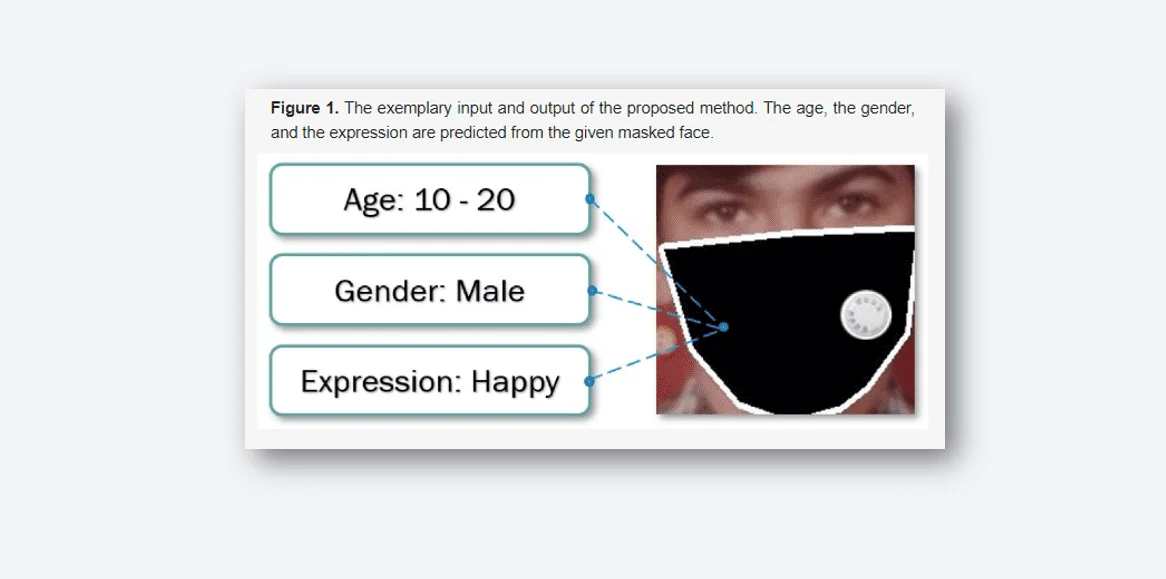
The key part of the process is making the dataset. Gathering pictures of people with different ages, genders, and expressions wearing masks is really hard. So, we came up with a way: we used pictures of faces without masks from a collection called FGNET and then added masks and labels ourselves. We ended up with 925 pictures, each with labels telling us about age, gender, and expression. We used a tool called OpenPose to find points on the faces in these pictures. Then, we made masks using the Pillow package. Since 925 pictures aren't enough to teach a computer well, we made four versions of each picture with different mask colors. This gave us 3404 pictures with masks that the computer could learn from. We sorted the pictures into groups based on age, like under 10, 10 to 20, and so on, to make things fair. We also labeled the pictures with Male or Female for gender and Happy, Neutral, or Unhappy for expressions.
So, in total, we had 1400 pictures of people under 10, 1010 pictures of those aged 10 to 20, 720 pictures of those aged 20 to 40, and 274 pictures of people over 40. For genders, there were 2000 Male and 1404 Female pictures. And for expressions, there were 1800 Happy, 950 Neutral, and 654 Unhappy pictures. You can see what this dataset looks like in a figure.
The two distinct methods, single and multi-task learning, represent contrasting approaches in machine learning. In the single-task learning paradigm, a model is designed and trained to perform a specific task, optimizing its performance for that particular task alone. This approach is straightforward and often yields good results when dealing with isolated tasks.
On the other hand, multi-task learning involves training a single model to perform multiple tasks simultaneously. This approach capitalizes on potential shared information across tasks to enhance the model's overall performance. By jointly learning from related tasks, the model can potentially develop a more comprehensive understanding of the underlying data distribution, leading to improved generalization and better performance on all tasks involved.
We tested our newly created dataset using the more complex ResNet152 network, which has a higher number of convolutional layers and maximum pooling, totaling 60,430,849 parameters. This was done to compare its accuracy against the traditional CNN model with only 7,654 parameters. The ResNet-152 utilized pre-trained weights from ImageNet for training, excluding the top fully connected layers and fine-tuning with 137 layers out of 152. For a single model approach, we explored employing Local Binary Pattern (LBP) and Eigenfaces with an SVM classifier . LBP, a basic texture operator, assigns binary values to pixels based on thresholded neighborhood pixel values. After preprocessing, the dataset was transformed into decimal numbers and used for SVM classification with a linear kernel. This separation was applied for age, gender, and expression models. The results favored deep learning over the LBP-SVM approach. Additionally, we attempted using Eigenfaces with PCA on SVM models, but this yielded worse outcomes compared to the LBP method.
Multi-task deep learning (MTDL) is an approach where multiple learning machines are collaboratively trained, allowing knowledge gained from one task to aid others. This is achieved by sharing parameters, with two main architectures: hard parameter sharing (used in this study) and soft parameter sharing. In the hard sharing method, the parameter set is divided into shared and task-specific ones. Typically, MTDL models with hard parameter sharing comprise a common encoder that then splits into task-specific components.

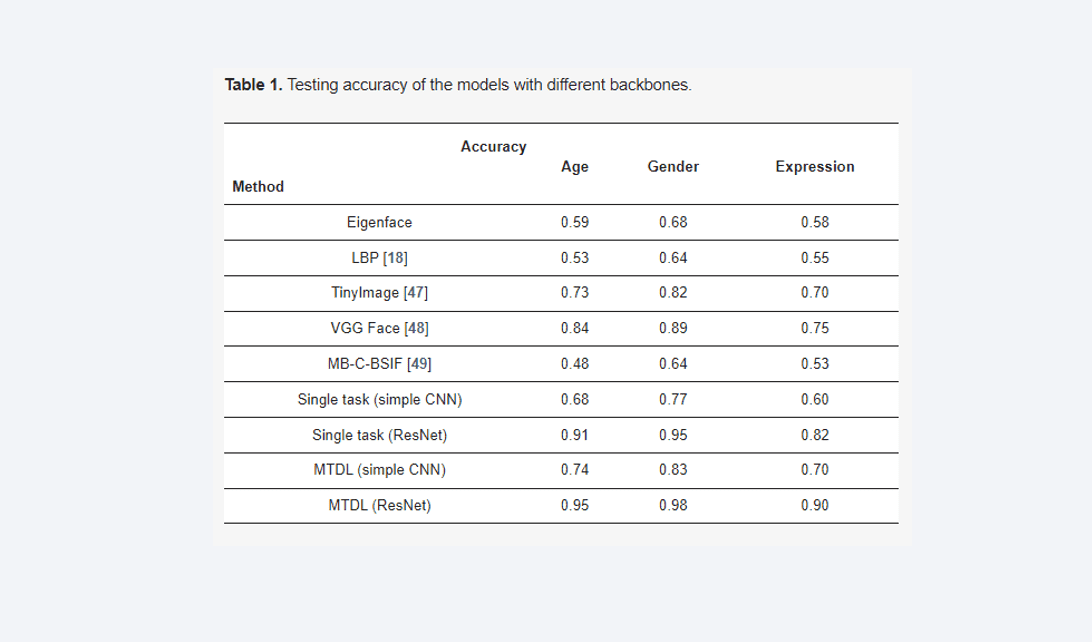
we compare our proposed approach for analyzing masked faces with two different implementations: a basic Convolutional Neural Network (CNN) and ResNet-152. We also contrast a single model with a multitask learning model. Various baseline methods, including EigenFace, LBP, TinyImage, and VGG Face, were employed for evaluation using the FGNET-MASK dataset's testing set. Accuracy is our primary performance metric, represented as the sum of true positives, true negatives, false positives, and false negatives for each classification task. For the single model, we developed three models using different backbones and approaches. Deep learning models outperformed SVM-based methods like LBP and SVM. The SVM method, utilizing linear SVM, exhibited mixed results among the different feature extraction techniques. Our simple CNN achieved accuracy rates of 0.68 for age, 0.77 for gender, and 0.60 for expression. The more complex ResNet-152 yielded higher accuracy rates of 0.91, 0.95, and 0.82 for age, gender, and expression respectively. We then introduced a multitask deep learning (MTDL) model, which proved superior to single CNN models. The MTDL approach achieved testing precision of 0.74, 0.83, and 0.70 for age, gender, and expression respectively with simple CNN, while ResNet-152 exhibited even better results of 0.95, 0.98, and 0.9 for age, gender, and expression. This emphasizes the advantage of deeper backbones in multitask deep learning. It's worth noting that our work has potential applications in various contexts like surveillance systems and targeted advertisement.
So, we dived into the tricky challenge of recognizing faces with masks on – you know, when you can't see the whole face? To crack this, we got creative and built FGNET-MASK. It's this cool new set of masked face pics we made using various techniques. Then comes the techie stuff – we introduced this multi-task deep learning thing (MTDL sounds fancy, right?). Basically, it takes a shot at guessing someone's age, expression, and gender, all while they're masked up. And guess what? Our experiments went pretty well, like high-five well! Looking ahead, we're all about adding more variety to our data collection game. Also, we're not stopping – we're eyeing other datasets like RMFRD. Oh, and there's more – we're snooping around other masked face jobs, like figuring out those key facial points and even magically removing masks. Stay tuned! ✌️
We also gratefully acknowledge the support of NVIDIA Corporation with the donation of GPU used for this research.
Vatsa S. Patel, Zhongliang Nie, trung-Nghia Le and Tam V. Nguyen.
Department of Computer Science, University of Dayton, Dayton, OH, 45469, USA.